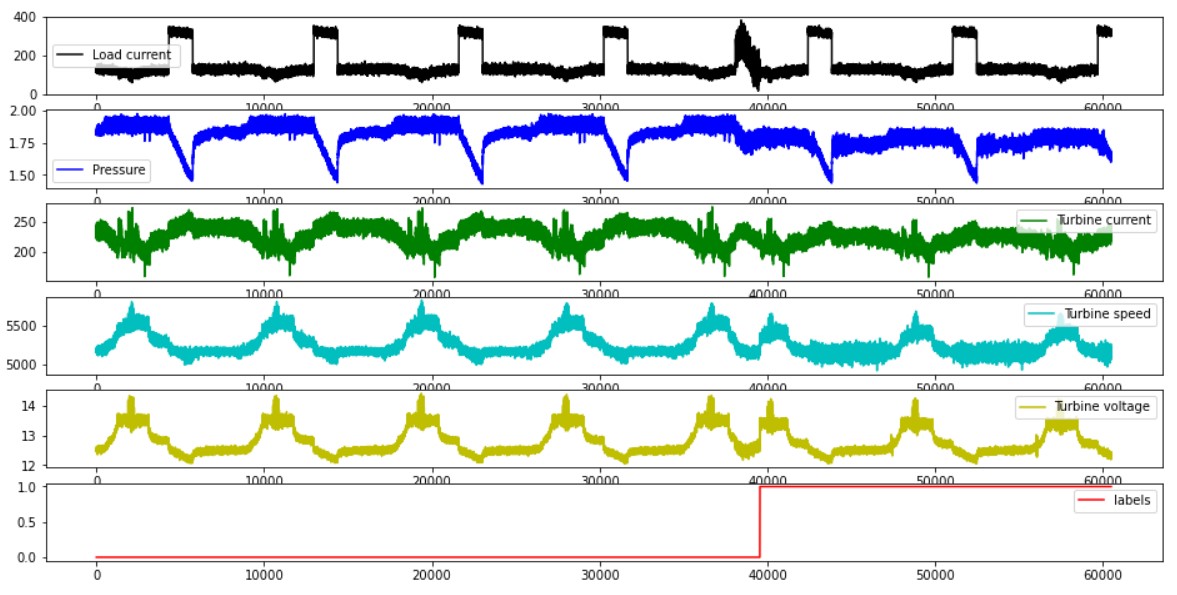
Solution final#
Phase 1#
In file phase1_all.py is the source code for our solution of phase 1 part. By running this file we get the prediction file in json format for unsupervised data.
Our pipeline consists of :
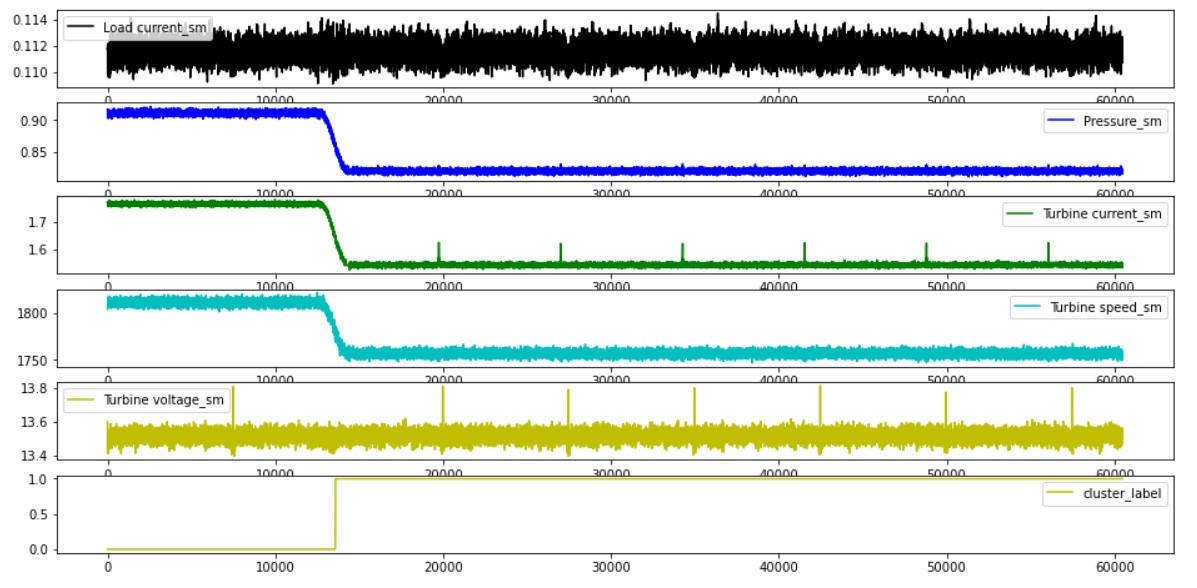
preprocessing data by smoothing attributes
we use k means clustering for detecting states and assigning the label to each data point. we also checked how clustering works by using PCA

if we only detect one state we compare with statistics of all weeks and based on that we have derived a threshold based on average pressure that we use to assign a state.

in the end we generate json file with solutions
Phase 2#
In phase two we concatenate the data for the past 10 data points and train the classifier on a subsample of all data (cca 10 percent). As the classifier we used the Logistic regression, the Dummy classifier and the Random forest classification. For the first ten predictions we always predict False as we do not have enough data to make predictions. We got the best results with the Dummy classifier.